Comentem nos comentários mais materiais se conhecer 🤝🏽
Glossário
Termo
Descrição
Chinchilla
Referência a um modelo de IA e princípio que indica o equilíbrio ótimo entre número de parâmetros e quantidade de dados para treinamento, visando eficiência máxima.
Scaling
Prática de aumentar o tamanho de modelos de IA, como número de parâmetros, com o objetivo de melhorar sua performance
Latência
Tempo que um sistema leva para processar uma entrada e gerar uma saída.
Drop loss
Termo informal usado para descrever a queda no valor da função de perda (loss) durante o treinamento de um modelo de aprendizado de máquina, indicando que o modelo está melhorando ao ajustar seus parâmetros para minimizar o erro entre as previsões e os valores reais.
MMLU (Measuring Massive Multitask Language Understanding)
Benchmark que avalia a capacidade de modelos de linguagem em múltiplas tarefas complexas.
Entropia
Grandeza da termodinâmica que mede o grau de desordem, aleatoriedade ou número de configurações possíveis em um sistema físico. Analogamente, em IA, representa a dificuldade crescente para melhorar a performance conforme o modelo se aproxima de seu limite ótimo, exigindo trabalho adicional para obter ganhos menores.
Shortfall
Em finanças, refere-se à diferença ou déficit entre o valor esperado e o valor efetivamente obtido, ou seja, a insuficiência de recursos para atingir uma meta ou obrigação financeira estabelecida.
Empírico
Algo que foi determinado ou comprovado por meio de observação, experimentação ou análise prática, ou seja, obtido da experiência real, não apenas da teoria.
Programação
Certamente esse é um tema bem amplo, dificil de trabalhar em apenas uma postagem, dito isto tentarei fornecer a perspectiva de como enxergo tudo isso, bem como expor minhas dúvidas de modo sincero, acredito que antes de ir mais além é importante termos uma definição clara do que seria essa ideia da programação em si,
A palavra solta por si só pode ser e significar coisas distintas a depender do contexto, programação pode ser a "ementa" de algo, pode ser a estrutura de um programa de TV por exemplo, uma rotina definida, a partir desse título você implicitamente infere que essa "programação" apresentada está atrelada à área de Ti, a noção de "escrever código" correto?
Pois bem, o dicionário aurélio traz a seguinte definição:
define programação como
A ação ou efeito de programar;
elaboração de um programa ou conjunto de programas;
plano ou lista das matérias de um curso;
reunião de eventos culturais ou artísticos a apresentar;
na informática, criação de programas de computador.
Trazendo mais para o contexto da engenharia de software temos de acordo com a ISO/IEC 12207 que o desenvolvimento (que inclui programação/codificação) é a transformação de um conjunto de requisitos em um produto ou sistema de software funcional.
Para quem é da área essa noção de tornar os requisitos em "produto" é algo rotineiro
Dentro do ciclo de desenvolvimento, para além da ISO temos a definição do SWEBOK (A "bíblia" da engenharia de software)
O SWEBOK Define
programação, ou construção de software, é definida como a criação detalhada do software através da combinação de codificação, verificação, testes unitários, testes de integração e depuração
perceba 5 sessões chaves,
Codificação: O processo de escrever o código-fonte do software usando uma linguagem de programação, implementando o design e especificações estabelecidas
Verificação: Revisar e examinar o código para assegurar que está correto, completo, consistente e aderente aos requisitos. Pode incluir revisões de código, inspeções e análise estática.
Testes unitários: Testes automáticos que verificam pequenas partes isoladas do código (funções, métodos ou classes) para garantir que funcionam conforme o esperado. Eles ajudam a localizar erros precocemente e facilitam manutenção e refatoração.
Testes de integração: Verificam a interação entre diferentes módulos ou componentes do sistema para checar se funcionam juntos corretamente. Eles garantem que a combinação das unidades produzam o resultado esperado.
Depuração: Processo de identificar, isolar e corrigir erros no código por meio de ferramentas e técnicas, permitindo que o software funcione corretamente conforme especificado.
Perceba que a "programação" como noção de construção de software tem a codificação apenas como um de seus sub processos, ela não se "resume" a apenas "codificar".
Um pouco de história
Voltando um pouco no tempo, acho interessante pensar quando e por que surgiu a "programação"? um google simples vai dizer que essa noção nasce com a figura de ada augusta que é considerada a primeira programadora/programador da história por ter escrito o primeiro algoritmo destinado a ser processado por uma máquina, a Máquina Analítica de Charles Babbage.
Ada desenvolveu os algoritmos que permitiram à máquina computar os valores de funções matemáticas, além de publicar uma coleção de notas sobre a máquina analítica,
Ada Augusta
A história é bem mais do que isso claro, porém para quem quiser se aprofundar mais sugiro pesquisar mais sobre, o fato é que ela desenvolveu "[...] uma visão sobre a capacidade dos computadores de irem além do mero cálculo ou processamento de números, enquanto outros, incluindo o próprio Babbage, focavam apenas nessas capacidades."
Nesse sentido, dá pra pensar em "programar" como uma forma de ensinar o computador a "pensar", no caso, a seguir um ou mais algoritmos, algoritmos esses definidos pelo programador...
Mas e a IA?
IA enquanto Modelo generativo
Veja bem, é válido ressaltar que eu não sou nenhum especialista em IA, não sou nem na área de desenvolvimento quem dirá a IA que é um campo de estudo relativamente "novo", digo novo entre aspas porque geralmente temas assim estão há muito tempo sendo estudados no campo acadêmico,
Porém para esse post em específico eu realizei algumas pesquisas/estudos, dessa vez, nem tudo vai poder ser da minha cabeça (felizmente)
Mesmo assim é muito importante que você cheque se as informações passadas são verdadeiras e fidedignas, faça isso não apenas comigo mas com qualquer coisa que você ler por aí, seja criterioso.
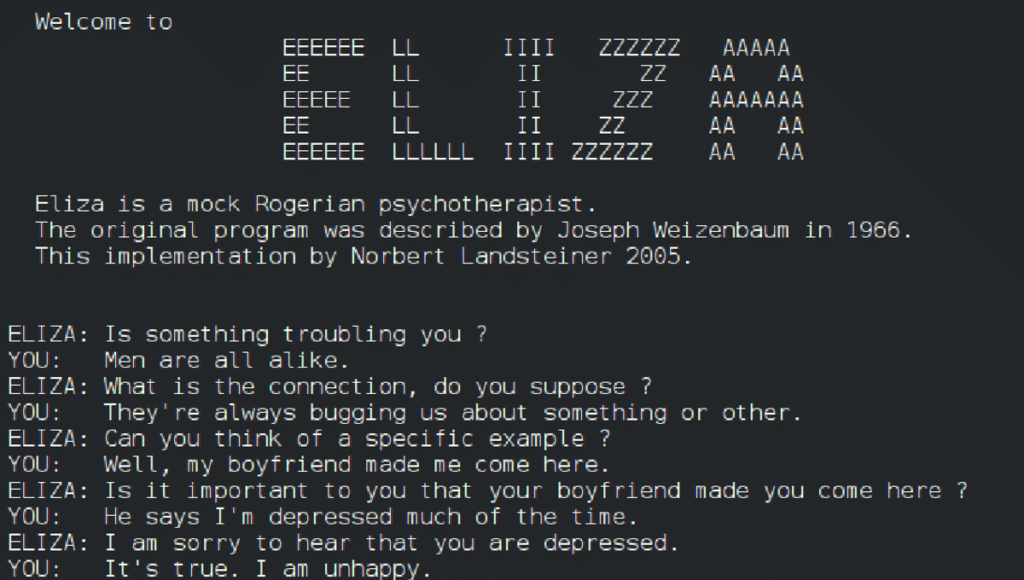
Desde 1960, já havia um indício do que nós conhecemos hoje por "chatbots", a Eliza por exemplo foi um programa criado por essa década a fim de simular conversas entre o ser humano e a máquina,
As pesquisas e artigos (Referências ao final para quem quiser ver/ler) sobre redes neurais e transformadores estão em vigor desde 2010 (Apesar da publicação mais tardia), os principais motores que viabilizaram os modelos de llm/chatbot como conhecemos hoje,
houve aí claro um considerável salto no tempo da minha parte, mas o intuito é claro o "ChatGPT" apesar de ser publicamente lançado pela OpenAi em 30 de novembro de 2022, sua concepção já estava em vigor desde muitos anos, a apresentação do chatGPT foi para muitos algo impressionante, isso trouxe cada vez mais evaluation (por parte de empresas como OpenAI e Nvidia) a ideia foi tomando cada vez mais hype, a "IA", furou a bolha e se tornou o novo marco da década, contrariando por exemplo expectativas do metaverso do markzuckerberg (No sentido de ser o próximo "grande" marco tecnológico).
A evolução da IA enquanto modelo generativo tem sido impressionante, isso é um fato, porém as pessoas no geral tendem a superestimar muito e por vezes exagerar demais, a "IA", os modelos generativos ainda não "pensam" e estão longe disso,
Nesse podcast por exemplo o Fábio Akita destrincha um pouco mais em detalhes essas nuances, ele não é especialista no campo de IA, mas é um dos brasileiros mais conceituados quando o assunto é programação no lado técnico da coisa.
Esse site "Rank de modelos da atualidade" mostra claramente um ranqueamento dos modelos lançados em relação a capacidade e tamanhos em bilhões de parâmetros usados para treinamento (ao longo do tempo desde que começou a tomar hype todo esse lance da IA).
Para além dos gráficos evolutivos dos modelos, talvez uma coisa obvia / nítida fica evidente, A cada modelo se nota claro uma melhora acentuada em relação ao modelo anterior, mas ao mesmo tempo, a melhora parece não ser tão "impressionante" assim, um exemplo, do GPT3 -> GPT4 Houve uma grande melhoria, evidente para todos, porém do GPT4 para o GPT5, esperava-se algo mais fora da caixa, as promessas e o hype que se tinha para o 5 não chegaram a serem concretizadas,
melhor em relação ao 4, porém como um 4.5 ou um 4 turbo, não o "5" que as pessoas esperavam ou tinham em mente.
Parte disso pode ser explicado pelo paradoxo de scaling, modelos cada vez maiores não tornam/fazem disso uma estratégia sustentável a longo prazo necessariamente.
A ideia vai além de uma observação empírica, o conceito central se baseia numa função matemática, "A lei de potência".
Lei de potência
L(N) = A * (N^-α) + erro irredutítvel
Onde:
L(N) = Perda de validação (loss) do modelo
N = Número de parâmetros
α ≈ 0.07 a 0.09 (A partir de uma observação empírica)
A = Constante de normalização
Esta não é uma equação linear.
O que isso significa?
A equação mostrada não é linear porque o número de parâmetros (N) está elevado a um expoente negativo. Em termos simples: aumentar N não faz L(N) crescer ou diminuir de maneira proporcional.
Expoente negativo
Conforme aumentamos N, o valor de N ^ -α diminui, mas essa diminuição acontece cada vez mais devagar.
Isso produz uma curva de decaimento: no começo, cada aumento em N reduz bastante a "loss"; depois, os aumentos passam a trazer ganhos cada vez menores.
Quando você plota os dados em escala log-log (logaritmo em ambos os eixos), a curva se torna uma reta. Esta é a assinatura matemática de uma lei de potência.
Sua linearidade em escala log-log prova que as melhorias de performance não crescem linearmente com os parâmetros - elas crescem em padrão de decaimento exponencial
O gráfico abaixo ilusta isso
Um exemplo exemplo da aplicação disso aparece nos ganhos reais dos modelos avaliados por benchmarks, como o MMLU.
Veja o padrão nos dados
Da extração do gráfico extraído a partir desse site, percebe-se que os ganhos de performance não são uniformes:
Transição
Ganho MMLU
Ganho %
Custo Relativo
7B → 13B (≈2x)
+13 pontos
+30.9%
1.86x
13B → 30B (≈2x)
+10 pontos
+18.2%
2.3x
30B → 70B (≈2x)
+7 pontos
+10.8%
2.3x
70B → 200B (≈3x)
+10 pontos
+13.9%
2.8x
Perceba que à medida que se duplica o número de parâmetros, os ganhos em MMLU diminuem ou se mantém (de modo progressivo): 13 → 10 → 7 → (3x mais) 10, uma manifestação numérica de retornos decrescentes.
Por que isso acontece?
Geometria da Aprendizagem
De acordo com algumas explicações, isso se dá pela geometria do aprendizado neural.
Cada característica ou conceito que um modelo aprende contribui de forma decrescente para reduzir a perda geral.
As características mais importantes (semântica básica, sintaxe, conhecimento fundamental) são aprendidas primeiramente, gerando drops de loss.
À medida que o modelo cresce, ele aprende características progressivamente menos importantes.
Para uma melhor assimilação, imagine-se estudando para um exame/prova. As primeiras 10 horas de estudo melhoram seu desempenho geral dramaticamente (supondo 60 -> 70), outras 10 horas podem adicionar mais 10-15 pontos (70-85), agora as últimas 10 horas talvez adicionem 3-5 pontos. O conhecimento geral necessário foi aprendido, o que restará serão os detalhes que farão a diferença do 85 -> 100.
Da mesma forma, um modelo 7B aprende os padrões fundamentais da linguagem. Um modelo 70B aprende estes mesmos padrões mais profundamente, mas adiciona principalmente refinamentos
os retornos decrescentes se tornam verdadeiramente problemáticos é na relação entre custo computacional investido e ganho de performance obtido
Fator crítico: Computação vs. Ganho
Pesquisadores do DeepMind descobriram que para um orçamento de compute fixo, a alocação ótima segue uma proporção de aproximadamente 1:1 entre parâmetros e tokens de treinamento. Um modelo 70B com compute-optimal deveria ser treinado com ~1.4 trilhão de tokens (razão 20:1).
No entanto, praticamente todos os modelos modernos violam esta proporção intencional:
GPT-3: ~300B tokens para 175B parâmetros (razão 1.7:1)
Llama 3 70B: ~15 trilhões de tokens (razão 200:1)
Phi-3: ~870 tokens por parâmetro (razão 45x Chinchilla)
Por que fazem isto? Porque adicionar mais parâmetros além do ponto de Chinchilla
requer cumulativamente menos dados mas exige muito mais computação total.
Para uma melhoria de 2x em perda (performance dobrada, grosso modo):
Abordagem A: Aumentar parâmetros em 1.4x (custa 1.15x mais compute)
Abordagem B: Aumentar tokens de treinamento em 2.8x (custa 2.8x mais compute)
Mas para modelos maiores que 70B, a realidade é que você precisa adicionar ~5-10x de compute para ganhos de apenas 10-15% em benchmarks.
Fenômeno da saturação de Benchmark
O MMLU (Measuring Massive Multitask Language) quando introduzido em 2020, tinha o GPT-3 pontuando apenas 43.9%.
Em 2024, Modelos como Claude 3 Opus e GPT-4 atingiram ~90%. Um progresso claro, mas há também um problema fundamental: benchmark saturation.
Benchmark saturation: ocorre quando os modelos aproximam-se do teto de dificuldade do teste, não necessariamente de verdadeira compreensão. Foi descoberto no MMLU ter ~6.5% de questões com problemas (respostas ambíguas ou incorretas).
Em resposta, desenvolveram o MMLU-Pro e posteriormente o Humanity's Last Exam (HLE) com 3.000 questões de especialistas.
No HLE:
GPT-4: ~88% no MMLU, mas apenas ~40% no HLE
Gemini 3: ~85% MMLU, ~35% HLE
Claude 3: ~90% MMLU, ~40% HLE
Isto sugere que os ganhos observados nos últimos 2-3 anos podem ser parcialmente ilusórios, artefatos de overfitting em benchmarks específicos, não melhorias genuínas em capacidade de raciocínio.
Custos ocultos: Engergia e Latência
Quando analisamos o avanço dos modelos de linguagem, não podemos olhar só para sua performance “numérica”, mas também para o que está “por detrás dos panos”: consumo de energia, latência (tempo de resposta) e preço de computação.
A tabela abaixo mostra como, conforme aumentamos drasticamente o tamanho dos modelos (em bilhões de parâmetros), os ganhos reais de desempenho ficam cada vez menores em proporção ao custo:
Transição
Ganho MMLU
Ganho %
Custo Relativo
7B → 30B (≈4x)
+23 pontos
+54.8%
2.8x
30B → 70B (≈2.3x)
+7 pontos
+10.8%
1.8x
70B → 400B (≈5.7x)
+15 pontos
+20.8%
6x
Os modelos 7B-30B oferecem o melhor custo-benefício: cada ponto percentual adicional em MMLU custa 1.2x a computação.
Modelos 70B+: cada ponto percentual custa ~2.4 - 4x a computação adicional.
Esse fenômeno é muito parecido com o conceito de entropia na física: quanto mais otimizado e “organizado” o sistema/modelo já está, mais difícil e caro fica melhorar ainda mais.
O que sobe e o que não sobe linearmente
Relações
Exemplos/Detalhes
Comportamento
Performance vs. parâmetros
f(n) = A · N^(-0.07) (ganhos desaceleram)
Não-linear (Retornos decrescentes)
Tokens para Chinchilla-ótimo
Volume de dados cresce menos que os parâmetros (sublinear)
Não-linear (Sublinear)
Latência em modelos grandes
Aumento desproporcional para modelos acima de ~30B parâmetros
Não-linear (Superlinear)
Consumo de energia vs. FLOPs
Gasto energético acompanha o número de operações matemáticas
Aproximadamente linear
Latência vs. tamanho em chips eficientes
Com hardware otimizado, latência segue proporcional ao tamanho do modelo
Aproximadamente linear
A conclusão mais importante disso é: a era do "escalonamento puro terminou", O ponto de Chinchilla foi aproximadamente atingido (70B com 1.4T tokens é computacionalmente ótimo para aquele nível de performance). Ganhos futuros virão de
Arquitetura (transformers mais eficientes, MoE melhorado)
Dados (curação de dados de qualidade suprema, synthética data)
Alinhamento (RLHF, Constitutional AI)
Teste (raciocínio em tempo de execução, multi-step verification)
Investimentos e negócios
Perspectiva do mercado financeiro (agora em 2025)
há sinais reais e mensuráveis de que os investidores estão começando a perder confiança na narrativa de IA, e a questão de uma bolha iminente é não apenas legítima, mas está se tornando a conversa central em Wall Street.
1 - nunca se investiu tanto em IA enquanto simultaneamente se vê retorno praticamente zero
Quando startups de software estão cortando 30% da força de trabalho e pagando menos por pessoas que fazem o mesmo trabalho (substituídas por IA), o que isto sugere? Que a IA é valiosa? Ou que as valuations das empresas estão tão infladas que precisam cortar qualquer coisa para justificar o custo?
Por um lado:
Investimento em IA continua recordista ($192.7B em 9 meses)
IA se torna boring infrastructure (como cloud em 2015-2020)
Economia sofre slowdown moderado (-1 a -2% GDP)
Cenário 2 (30% de probabilidade): Crack Abrupto
DeepSeek ou competitor cria modelo 10x mais barato/eficiente
Paradigma de scaling massive muda de repente
Nvidia/TSMC stocks caem 50-70%
S&P 500 sofre correção de 15-25%
Cascata de falências em mid-tier startups
1-2 recessão moderada nos EUA
Cenário 3: AI Justifica Hype
Breakthrough genuíno em AGI ou aplicações killer
ROI explode em 2026-2027
$2 trilhão de receita esperada se materializa
Investimento atual prova ser presciente, não louco
É claro que é impossível prever exatamente o que vai acontecer, o que temos aqui são algumas possibilidades / probabilidades,
IA e os desenvolvedores
No contexto do boom da IA, todas as áreas profissionais foram e estão sendo afetadas de algum modo, e isso inclui claro, os profissionais de tecnologia, que estão no cerne de todas essas mudanças, é interessante como a cada modelo novo das big techs, as pessoas sempre vão no tt falar: "OH meu DEUS, Its over!!", mas é claro que isso é intencional, nenhum CEO ou alguém que trabalha justamente no marketing ou com IA nesse sentido irá vender uma imagem negativa dela, os videos demo apresentativos sempre mostram um modelo "perfeito" naquilo que ele propõe, é preciso afinal manter os acionistas acreditando no projeto, gerar hype pra continuar mantendo o capital de investimento
Com tudo isso, é impossível negar a influência que ela está tendo, o impacto indireto e direto em nossas vidas, na minha visão, o ponto forte da IA (enquanto modelo generativo) não está somente no modelo, mas principalmente pela pessoa que usa,
Espadas foram criadas para serem armas de combate, quanto mais afiada a espada, mais facilmente ela cortaria seu oponente, porém, uma espada nas mãos de um soldado treinado e uma espada na mão de um civil sem conhecimento prévio produziriam o mesmo resultado?
Talvez sim, cortaria o oponente, mas consistentemente, os resultados seriam o mesmo?
Se você pensar na IA nesse sentido, imagine que qualquer um hoje pode ir lá e criar sua "landing page" com um modelo como gemini 3, ou alguma plataforma paga de IA para isso.
Porém essa mesma IA nas mãos de um desenvolvedor poderia ir além, em tese ele deveria saber melhor prompts, onde ela estaria "fazendo caquinha" ou realmente ajudando, dum ponto de vista de visão ele saberia o que melhor perguntar para trazer resultados melhores e mais rápidos. etc.
Pode chegar o dia em que a IA produza código tão bem quanto um desenvolvedor sênior, a questão é, quem fará as perguntas? mesmo que se saiba o que quer, saberão explicar exatamente de modo que produza o resultado esperado?
Na coleta de requisitos para a produção de um sistema, é muito comum que volte várias vezes num mesmo requisito, porque por muitas vezes o cliente apesar de saber o que quer a descrição de seu problema não é exatamente aquilo que ele espera.
A IA até então tem se tornado uma boa ferramenta mas como toda ferramente ela tem suas limitações.
O que você fará se na sua aplicação tiver um problema crítico de segurança e você não tiver mais tokens?
O que você fará se de repente a internet cair e você não poder recorrer ao chat gpt?
cenários improváveis, hipotéticos, mas perceba, eu acredito que ela (A IA) dê um boost e te ajude naquilo que você já sabe, não naquilo que não sabe, ou não faz ideia.
Então não, a IA não vai "acabar" com os desenvolvedores, pelo menos não por enquanto : )
O que pode acontecer (que já está acontecendo), ela mudar bastante a forma que trabalhamos, porém substituição, não.
O que você acha/pensa disso tudo?
Comenta/compartilha com alguém!